Hyperparameter Tuning
Hyperparameter tuning is search.
Common approaches
- Randomized Search
- randomly try different combinations
- narrow down the search space and identify promising hyperparameters
- Grid Search
- try all possible combinations of hyperparameters
- perform a more exhaustive search around the identified hyperparameters
- Coordinate-wise gradient descent
- change them one at a time, accepting any changes that reduce testing error
- Bayesian hyperparameter optimization/AutoML
- start with hyperparameters that worked well for similar problems
Hyperparameter Tuning in Deep Learning
Ordering the needs of tuning
- learning rate
- the most important hyperparameter to tune
- variants
- scheduled learning rate (e.g. continuously decreasing rate, like Gradient Descent#Learning rate decay)
- adaptive learning rate (e.g. Gradient Descent#Adam (Adaptive Moment Estimation))
- momentum term (if you use Gradient Descent#Momentum)
- good default = 0.9
- number of hidden units
- probably second most important
- depth (number of hidden layers)
- learning rate decay
- depending on your Gradient Descent#Types of Gradient Descent, there can be also
- mini-batch size
- adam (Gradient Descent#Adam (Adaptive Moment Estimation))
- always work with
=0.9, =0.999, =1e-8
- always work with
Tip
Unfortunately, learning rate and depth interact. In general, deeper networks need smaller learning rates.
How to search hyperparameters
- use Randomized Search instead of Grid Search
- use an appropriate scale for hyperparameters, e.g. log scale
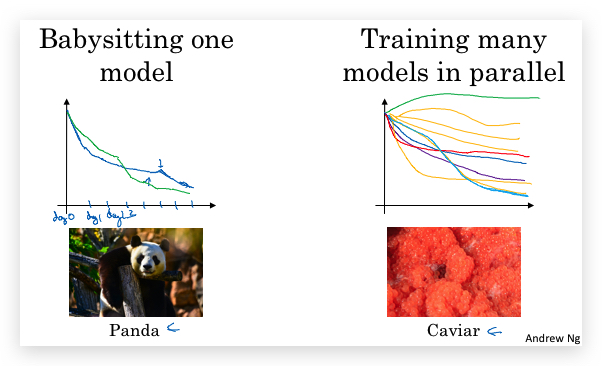
- can try different strategies: Panda vs. Caviar